
MongoDB Aggregation - A Beginner guide
The beginners guide to working with aggregation in MongoDB


One crucial component of the MongoDB database that many engineers avoid is MongoDB aggregation. Not just junior engineers, but also some senior class engineers, and the main reason for this is that it is intended to be thought that aggregation is just too difficult to deal with, and that alone is sufficient justification to avoid it. But when it comes to creating a well-scalable application using MongoDB as the database, aggregation plays a very important role.
This article will cover topics of aggregation that are perceived to be complex and will simplify them through the use of real-world use examples.
Prerequisite
A Junior level knowledge and understanding of Databases
A piece of basic knowledge of MongoDB
Understanding MongoDB just a little better
Before delving into MongoDB aggregation, keep in mind that MongoDB is a NoSQL database, which means it is not organized into tables, attributes, columns, and the like. This makes it a little strange to work with when you need to combine two or more collections (known as tables in SQL databases) to generate data/results. When working with SQL databases, doing operations such as Joins, Sum, Average, and so on is rather simple. This is what MongoDB aggregation was created to address. What exactly is aggregation in MongoDB?
What is Aggregation?
Aggregation is a process of working with a large number of documents or data by passing them through several phases. The coming together of these phases is known to be called a pipeline. Several things can be considered and implemented within these phases such as filtering, sorting, modification, etc. Let’s bring this into MongoDB. Aggregation in MongoDB is a process of having a document or group of collections pass through several stages (listed above) in a pipeline.
Working with a real-life scenario where you are a manager in several manufacturing companies, and you need to develop a report where you want to retrieve the kinds of products these companies manufacture. you will be taking into consideration the company's profiles and also the products which each of these companies manufactures. In a well-structured application, the products will be stored in a separate collection just as the company's information like name, location, year Founded, and so on. Having to perform some operations like retrieving all companies that produce coffee, the total number of milk produced by all the milk-producing companies, and many more scenarios you can think of, will be a difficult one and this is where aggregation plays a role. It helps to simplify operations that are seen to be cumbersome and could affect memory load in your application. Let’s talk about the aggregation pipeline before delving into some aggregate operations.
What is an aggregation pipeline and what role does it play?
The aggregation pipeline allows you to transform and modify data in a very flexible way. It consists of a series of stages that are applied to a document or data. It helps in allowing you to perform complex modifications to data. There are several stages that we have to consider which are:
Filtering ($match); This stage allows you to work with only information which is related to what you need while performing your modification. It filters out information or data that matches the condition inputted in the match syntax.
Grouping ($group); This stage does the aggregation job right after the stage above (filtering) and this further simplifies the document to only contain needed data.
Sorting ($sort); This stage sorts the grouped data in the way and manner in which it is needed. For example; the sorting could be in ascending order.
Having explained that, Let’s play around with some data and aggregate operations. We will be working with the data below and for our test case, we will be using the mongo playground editor. If you are using the same editor, you should have an interface like the one below:
Below is the data we will be working with. Copy it and paste it into the editor (in the database section):
db={
"companies": [
{
"_id": 1,
"name": "Company A",
"industry": "Technology",
"location": "San Francisco"
},
{
"_id": 2,
"name": "Company B",
"industry": "Technology",
"location": "New York"
},
{
"_id": 3,
"name": "Company C",
"industry": "Healthcare",
"location": "Chicago"
},
{
"_id": 4,
"name": "Company D",
"industry": "Finance",
"location": "London"
}
],
"products": [
{
"_id": 1,
"company_id": 1,
"product_name": "Product X",
"rating": 4.5
},
{
"_id": 2,
"company_id": 1,
"product_name": "Product Y",
"rating": 4.0
},
{
"_id": 3,
"company_id": 2,
"product_name": "Product Z",
"rating": 3.8
},
{
"_id": 4,
"company_id": 3,
"product_name": "Product W",
"rating": 4.2
},
{
"_id": 5,
"company_id": 4,
"product_name": "Product V",
"rating": 4.7
}
]
}
Now we have our data and editor ready, Let’s look into basic aggregate operations and write some queries.
Basic Aggregate Operations
- MongoDB $match Operation: The first of the basic operations we will be looking into is the $match. As said earlier, the match acts as the filter that helps to retrieve information that you want to work with to reduce the data complexity. For example, you can decide to work with only data whose company industry is technology. To achieve this, we will use the query below:
db.companies.aggregate([
{
"$match": {
industry: "Technology"
}
}
]);
This will give you the result:

- MongoDB $project Operation: The $project aggregate operation is used to filter out fields that are needed after using the $match syntax to filter out data that is required. You would notice that the $match query filters out the matching condition which automatically returns all the attributes for each data returned. With the project, you can decide to return only the industry and name fields. This can be achieved using the query below:
db.companies.aggregate([
{
"$match": {
industry: "Technology"
}
},
{
"$project": {
industry: 1,
name: 1
}
}
]);
This will give you an output/result as the one below:

- MongoDB $group Operation: The group operation allows you to perform a series of operations like getting the sum, average, minimum, maximum, etc of grouped data. Let’s take a lot of group operations like getting the sum of the grouped data. For example, you can decide to retrieve the total sum of all companies in each industry using this code below:
db.companies.aggregate([
{
$group: {
_id: "$industry",
totaldocs: {
$sum: 1
}
}
}
])
This will give you the result below:

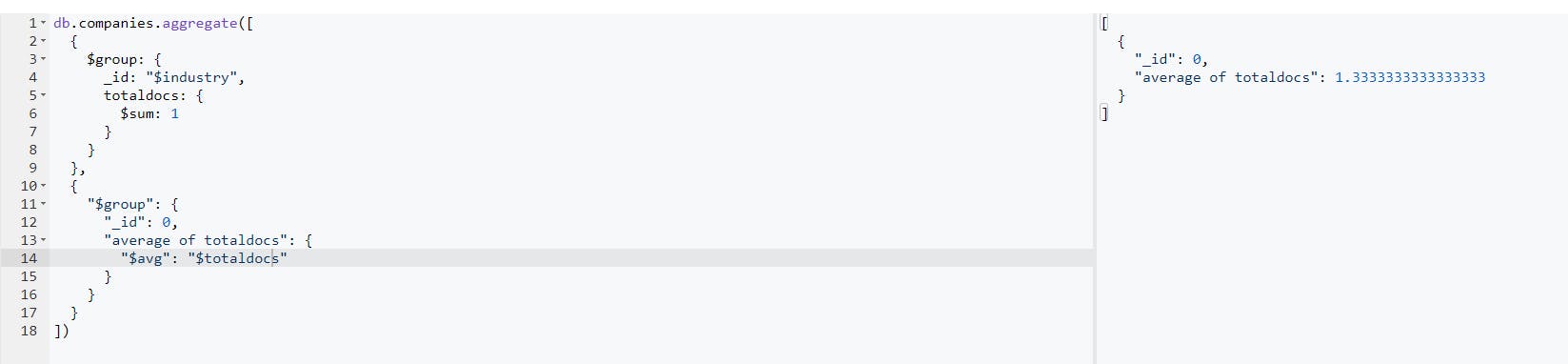
The above query groups the data by its industry and goes further to calculate the total number of companies that fall under each industry. You can also decide to retrieve the average number after getting the total sum. That can be achieved using the code below:
db.companies.aggregate([
{
$group: {
_id: "$industry",
totaldocs: {
$sum: 1
}
}
},
{
"$group": {
"_id": 0,
"average of totaldocs": {
"$avg": "$totaldocs"
}
}
}
]);
This will give you the result below:
The group aggregation operation has other operations like the $min, $max, $push, etc which you can extensively study through the studio3T documentation of aggregate.
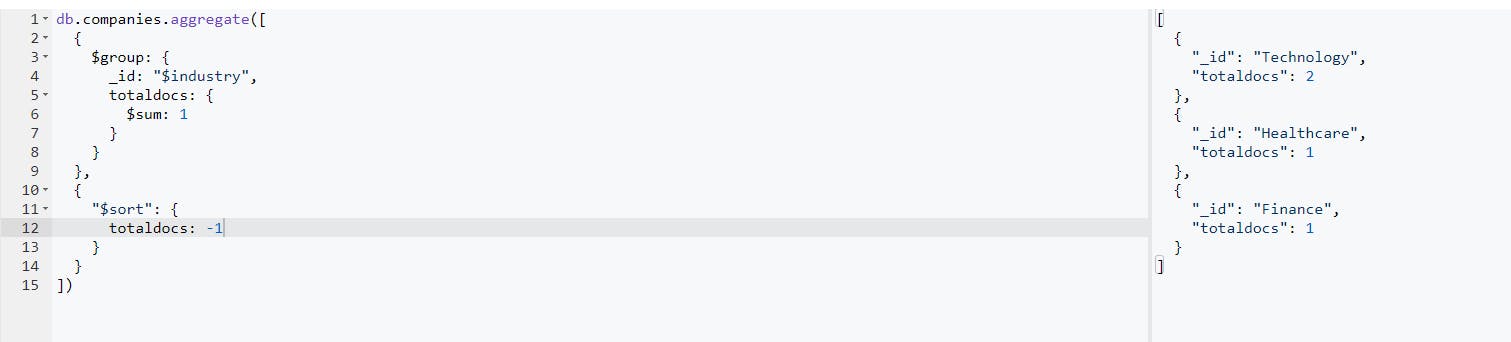
- MongoDB $sort Operation: The sort aggregate operation is used to display the modified result in a particular form or order. For example, the result obtained from the group operation can be returned in descending order using the query below:
db.companies.aggregate([
{
$group: {
_id: "$industry",
totaldocs: {
$sum: 1
}
}
},
{
"$sort": {
totaldocs: -1
}
}
]);
This will produce the result below after the operation has been carried out:
Having looked at several operations that can be carried out using the mongoDB aggregate method, these are just the basic operations that you will always need to use while working with the aggregate. We also have some more technical use cases of aggregate functions and for more technical cases, it will warrant the use of some advanced operations within the aggregation pipeline. These operations help to achieve some desired results that cannot be achieved by just using the basic aggregate operations or other simple MongoDB queries. Now, let’s go a bit deeper into the aggregation journey by dealing with some of its advanced operations.
Advanced Aggregate Operations
As with any other technology, framework, library, or package, there is always an advanced element of it that comes up when dealing with higher challenges and is required to solve those types of problems. The aggregate is not forgotten because it has certain sophisticated operations that aid in the resolution of advanced use cases. The following operations will be considered:
- MongoDB Lookup ($lookup): If you are coming from the SQL world, you will find lookups similar to joins in SQL because they do similar things. The use of lookup is to be able to work with more than one collection. For cases where data or information is meant to be retrieved by combining more than one collection, the lookup plays a part and helps to achieve that. For our use case, we are working with two collections (companies and products). Now let’s take this example: We want to retrieve all companies (and their products) whose industry is of value: “Technology”. This can be achieved using the query builder below:
db.companies.aggregate([
{
$match: {
industry: "Technology"
}
},
{
$project: {
_id: 1,
name: 1,
industry: 1
}
},
{
$lookup: {
from: "products",
localField: "_id",
foreignField: "company_id",
as: "Technology companies"
}
}
]);
The execution of this query will give us the result:
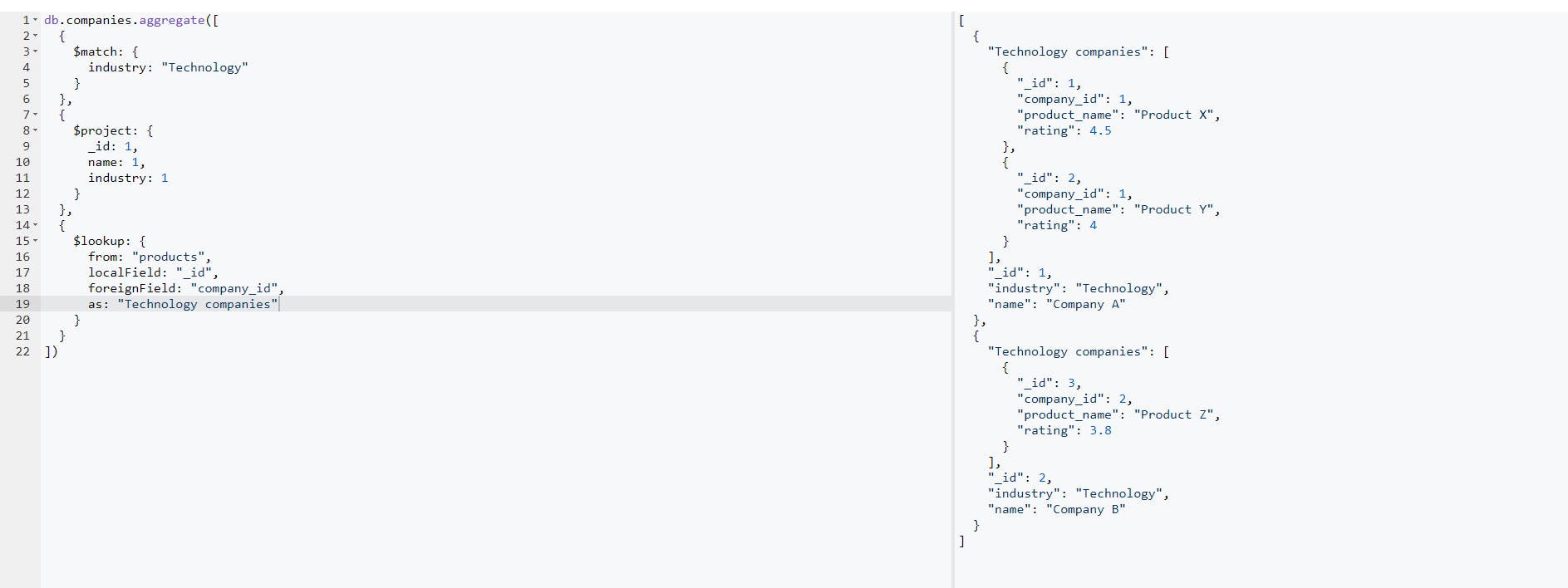
Let’s look into this complex query sequentially:
The first step in the pipeline was to filter out using the match. We filtered the companies so we can work with companies whose industry is of value: “Technology”. If we take that as a standalone query, we will get the result below:
Query:
db.companies.aggregate([
{
$match: {
industry: "Technology"
}
},
]);
Result:
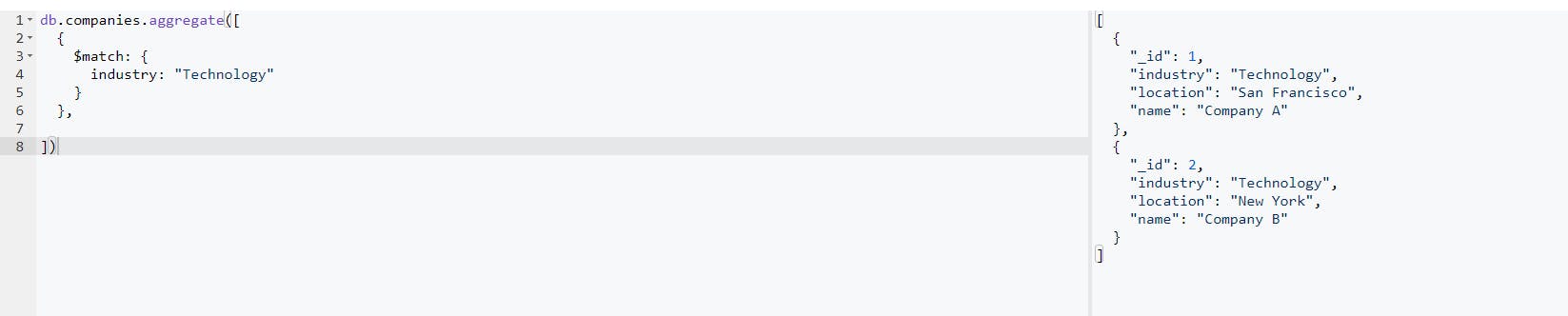
We went on to use the project syntax to filter out the attributes we'd be working on within the next stage. The first syntax ($match) returns all attributes and fields, but in our instance, we just need the industry and name fields, as well as the _id, which is returned by default. To accomplish this, we added the following query to the original query:
Query:
db.companies.aggregate([
{
$match: {
industry: "Technology"
}
},
{
$project: {
_id: 1,
name: 1,
industry: 1
}
},
]);
Result:

Finally, we used the $lookup to join the companies and the products table to extract product information of companies whose industry is technology. We then added the last part of the aggregate operation to achieve the desired result which we had above:
{
$lookup: {
from: "products",
localField: "_id",
foreignField: "company_id",
as: "Technology companies"
}
}
We’ve seen in a detailed form how to make use of the lookup aggregate operation to extract data from more than one collection.
MongoDB Unwind ($unwind): The unwind aggregate operation is a pipeline stage that helps to deconstruct an input that has an array in its document. It helps to produce a separate document for each of the array elements. To see the practical use case of this operation, you will update the "companies" data from what you had before. Now go into the editor in the database section and update the companies data to this below:
"companies": [ { "_id": 1, "name": "Company A", "industry": "Technology", "location": "San Francisco", staffs: [ { year: 2020, number: 988 }, { year: 2021, number: 1034 }, { year: 2022, number: 345 }, { year: 2023, number: 8956 } ] }, { "_id": 2, "name": "Company B", "industry": "Technology", "location": "New York", staffs: [ { year: 2021, number: 800 }, { year: 2022, number: 200 }, { year: 2023, number: 450 } ] }, { "_id": 3, "name": "Company C", "industry": "Healthcare", "location": "Chicago", staffs: [ { year: 2021, number: 2345 }, { year: 2022, number: 9007 }, { year: 2023, number: 1234 } ] }, { "_id": 4, "name": "Company D", "industry": "Finance", "location": "London", staffs: [ { year: 2021, number: 1534 }, { year: 2022, number: 2345 }, { year: 2023, number: 457 } ] } ],Now you have an updated form of company data which shows the staff size of each company for the last 3 years. You would notice that the staff property is of type array and the aggregate cannot perform an operation directly on that type of data type because of its nature. This is where the unwind plays a vital role by forming a simpler document for each of the array values. We would achieve this by using the query builder below:
db.companies.aggregate([ { $match: { name: "Company A" } }, { "$unwind": "$staffs" } ]);And this will give us the result as this one below:
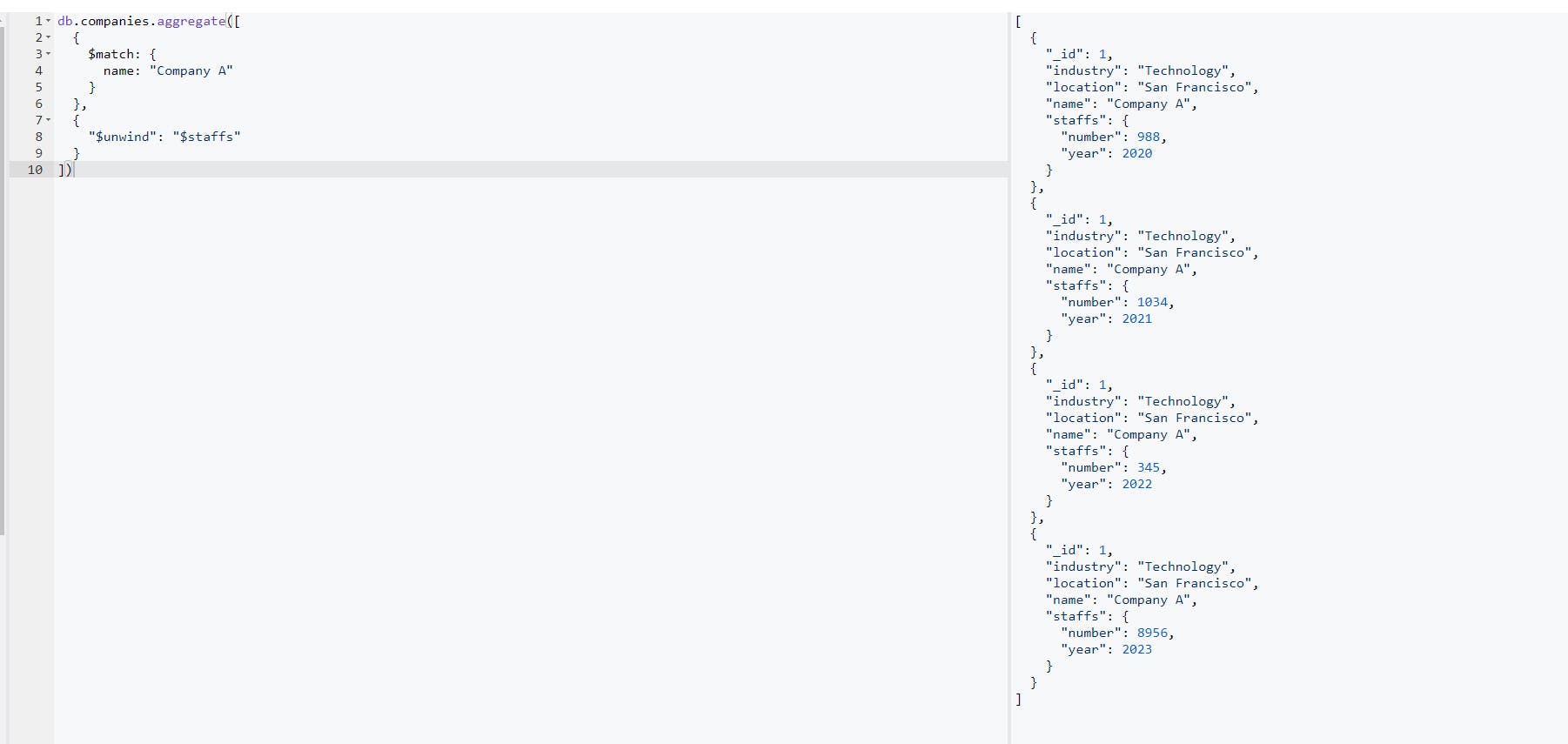
Looking at the result above, you can see that the unwind has assisted us in creating easier data for each staff year whose firm name is "Company A." This allows us to simply work with other aggregate operations such as the group, project, and so on.
Conclusion
So far, we have been able to delve into aggregate from the very basics of explaining why to use it and what it is all about by looking at basic aggregate operations and also covering some advanced operations too. All operations that we discussed play a vital role when working with complex data and in getting to use them, you have to understand what exactly you want to achieve before going ahead to make use of any of the operations. With that being said, there are still some more complex parts of aggregate usage and I will be making an article on the advanced parts like $facets, working with arrays ($push, $pop, $addToSet, $map, etc), aggregate optimizations and much more which were not covered in this beginners guide.
Congratulations if you've made it this far in the article. I can assure you that with the extensive explanation in this article, you'll be able to comfortably navigate most aggregate-related challenges. Keep an eye on your notifications for the second part of this post, which will go through the more advanced topics.
Support
If you found this article helpful and interesting, I would appreciate the comments, likes and also contributions to anything that was meant to be covered and was omitted. We all learn new things every day, and believe me, I am open to learning new things from anyone, at any moment. Kindly follow me for further articles on various Frontend and Backend aspects of software engineering.